

原标题:CVPR 提前看:视觉常识的最新研究进展
机器之心分析师网络
作者:仵冀颖
编辑:Joni Zhong
2020 年 CVPR 将于 6 月 13 日至 19 日在西雅图举行。今年的 CVPR 有 6656 篇有效投稿,最终录用的文章为 1470 篇,接收率为 22%。作为计算机视觉三大顶会之一,CVPR 今年的论文方向依然为目标检测、目标跟踪、图像分割、人脸识别、姿态估计等等。CVPR 是老牌的视觉、图像和模式识别等研究方向的顶会,本篇提前看中,让我们在人工智能、深度学习热潮的冲击下,一起关注一下视觉常识的最新研究进展。
具体的,我们关注下面四篇文章:
1、What it Thinks is Important is Important: Robustness Transfers through Input Gradients
2、ClusterFit: Improving Generalization of Visual Representations
3、Learning Representations by Predicting Bags of Visual Words
4、AdderNet: Do We Really Need Multiplications in Deep Learning?
1、What it Thinks is Important is Important: Robustness Transfers through Input Gradients

论文链接:https://arxiv.org/abs/1912.05699
这篇文章关注的是模型面对对抗样本时的鲁棒性的问题。在源任务和目标任务使用模型架构相同的情况,对扰动具有鲁棒性的权重在不同任务间也具有鲁棒性。本文作者选择了输入梯度(input gradient)作为不同任务间迁移的媒介,从而实现任务不可知和体系结构不可知的鲁棒性迁移,称为「输入梯度对抗匹配(input gradient adversarial matching (IGAM))」。之所以选择输入梯度,是因为鲁棒的对抗训练(Adversarial Training, AT)模型得到明显的输入梯度,而非鲁棒模型则给出有噪声的输入梯度,如图 1。每个像素的输入梯度定义了微小的变化如何影响模型的输出,并且可以粗略估计出每个像素对于预测的重要性。
IGAM 的核心思想是:训练一个具有对抗性目标的学生模型(student model)以愚弄鉴别器,使得鉴别器将学生模型的输入梯度视为来自一个鲁棒的教师模型(teacher model)的输入梯度。为了在不同的任务之间迁移,教师模型的逻辑层首先对目标任务进行简单微调,随后,在极大极小博弈中,冻结教师模型的权重,使用单独的鉴别器训练学生模型,以便学生模型和教师模型的输入梯度具有语义相似性。IGAM 的训练包括两个阶段:1)在目标任务上微调鲁棒的教师模型;2)在学生模型训练过程中,对抗正则化输入梯度。

图 1. CIFAR-10 图像非鲁棒模型(中间)和鲁棒模型(右)的输入梯度
首先,根据目标任务微调教师模型 f_t 的权重。将模型权重参数化为Ψ,微调阶段使用交叉熵损失训练模型:

我们使用微调的结果替换模型中的最终逻辑层,除逻辑层外冻结教师模型 f_t 的所有权重。将逻辑层前的所有被冻结权重表示为Ψ.^+,替换后新的逻辑层表示为Ψ_logit,得到教师模型的微调目标函数为:

在对目标任务的逻辑层进行微调之后,教师模型的所有参数(Ψ)都固定不变。
其次,下一步我们在学生模型的训练过程中进行输入梯度匹配:在目标任务数据集 D_target 上表征学生模型 f_s 的分类交叉熵损失为:

通过梯度反向传播,得到学生模型 f_s 的输入梯度为:

相应地,教师模型 f_t 的输入梯度为:

参考 GAN(包含生成器和鉴别器模型的框架)的思想,为了使学生模型的输入梯度与教师模型的输入梯度相似,定义对抗正则化损失函数如下:

同时考虑在目标任务数据集 D_target 上表征学生模型 f_s 的分类交叉熵损失函数 L_θ,xent,可以通过快速梯度下降(SGD)来优化,以近似得到如下的最佳参数:

鉴别器通过最大化对抗损失项来学习正确地区分输入梯度。将 f_disc 参数化表示为φ,同样使用 SGD 训练鉴别器:

此外,本文还引入 L_diff 来惩罚从同一输入图像生成的 Js 和 Jt 之间的 L2-norm 差异:

最终得到完整的学生模型 f_s 的训练目标函数为:

IGAM 的完整训练过程如图 2:

图 2. 输入梯度对抗匹配的训练过程
以及,代码如下:

最后,作者讨论了在不同维度的任务之间迁移的问题。为了沿与输入梯度相反方向的梯度传播损失,使用仿射函数来调整目标任务图像以匹配教师模型输入层的维度:

随后,可以计算教师模型的交叉熵损失如下:

由于仿射函数是连续可微的,可以通过反推得到输入梯度:

图 3 给出了令图像与教师模型输入维度的匹配转换的三个示例,分别为图像缩放、图像切割和图像填充。

图 3. 令图像与教师模型输入维度的匹配转换的示例
实验分析
本文在由 MNIST、CIFAR-10、CIFAR-100 和 Tiny-ImageNet 组成的源-目标数据对上完成了 IGAM 实验。图 4 给出了不同数据集中的输入梯度,与标准的模型相比,IGAM 模型的输入梯度噪声较少。表 1、表 2 以及图 5 分别给出了不同数据库中的实验结果,这些结果表明 IGAM 可以在不同的任务之间,甚至在不同的模型结构之间传递鲁棒性。

图 4. 不同模型的输入梯度
表 1. 迁移无噪和对抗性 CIFAR-10 测试样本的准确度

表 2. CIFAR-100 测试样本的准确度


图 5. Tiny-ImageNet 测试样本的准确度
小结
这篇文章讨论的是在图像处理的源任务和目标任务的模型架构相同的情况下,寻找在不同任务间具有鲁棒性的视觉相关的指标。本文作者使用的是输入梯度,并通过大量实验验证了其有效性。类似的,下一步研究可以探讨其它衡量输入梯度语义的指标,以及探讨引入其它指标或特征来实现对抗鲁棒性。
2、ClusterFit: Improving Generalization of Visual Representations

论文链接:https://arxiv.org/abs/1912.03330
通过引入自由标注,弱自监督预训练方法具有良好的适应性。但是,弱自监督预训练方法需要预先逼近一个代理目标函数,以及,假定这个代理目标函数与随后的转移主任务一致,通过优化该代理目标函数就能够生成合适的预先训练的视觉表示。这一假设在充分监督的预训练(fully-supervised pre-training)中基本能够保证成立,但是对于弱自监督学习来说,这很难保证。这篇文章探讨的问题是「 有没有一种方法可以解决弱自监督的预训练阶段对代理目标函数过度拟合问题?」作者的思路是:通过对代理目标学习到的特征空间进行平滑处理(smooth)来解决这一问题。本文提出一种简单的框架 ClusterFit (CF),该框架与经典的弱自监督预训练(迁移学习)之间的关系见图 1。一个经典的迁移学习框架包括两个阶段:预训练+迁移学习(即图 1 的上半部分),而 ClusterFit 相当于在这些阶段之间增加了一个步骤,即图 1 下半部分虚线引出的内容。在图 1 中,D_cf 表示 CF 框架引入的数据库,D_pre 是经典预训练数据库,D_tar 是测试目标数据库,N_pre 表示经典预训练网络,N_cf 表示 CF 框架引入的网络。

图 1. 完整的 ClusterFit(CF)流程
CF 框架介绍
CF 主要包括两步骤的工作,第一步,Cluster,给定一个使用代理目标函数和新数据集进行训练的网络,利用学习到的特征空间对该数据集进行聚类。第二步,Fit,使用聚类作为伪标签在这个新数据集上从头开始训练一个新网络,见图 2。

图 2. ClusterFit (CF) 结构
首先得到一个在数据库 Dpre 和标签 Lpre 中预训练的神经网络 Npre。使用 Npre 的预处理层从另一个数据库 Dcf 的数据中提取特征。接下来,使用 k-means 将这些特性聚集到 K 组中,并给这些聚类分配新分类「标签」(Lcf)。最后,基于 Dcf 利用交叉熵损失函数得到另一个网络 Ncf。
作者讨论了在受控设置下从「代理目标函数」训练学习到的特征的泛化程度。作者设置了这样一个实验场景:在 ImageNet-1K 数据库中,人为添加合成的标签噪声,目的是使得代理目标函数的预训练与下游的训练任务尽量不同。图 3 给出了不同的标签噪声 p 取值的 N_pre(即 CF 之前)和 N_cf(即 CF 之后)的迁移学习性能。在训练前存在大量的标签噪声的情况下,CF 仍然能够学习到可迁移的有效特性,对于更细粒度的目标任务,如 ImageNet-9K,CF 甚至可以改进有监督的 ResNet-50 模型(p=0)

图 3. 控制实验
实验分析
在 11 个公开的、具有挑战性的图像和视频基准数据集上,ClusterFit 显示出显著的性能提升,具体见表 1。ClusterFit(CF)适用于各种不同的预训练方法、模式和结构。
表 1. 实验结果汇总

在 CF 整体框架中,Npre、Ncf 的大小、预训练标签空间的颗粒度等,都会影响 CF 的效果。如图 4 的实验结果,在 Npre 容量较大的情况下,不同 K 取值能够保证有 2%—3% 的持续改进。这表明,具有较大容量的 Npre 能够生成更丰富的聚类视觉特征,从而提高迁移学习性能。图 5 中,迁移学习的性能随着 Dpre 预训练标签数量的增加 log-线性的增长。增加标签的数量是非常容易的,作者认为,该实验结果证明了 CF 在设计一个通用的预训练标签空间任务中的实用性。

图 4. Npre、Ncf 的选择影响

图 5. Npre 中标签数量的影响
小结
CF 是一个可伸缩的、通用的框架,对模型架构、数据模式和监督学习的形式没有任何限制。其中,聚类(Clustering)的处理可以看作是一种有效捕获特征空间中的视觉不变性的有损压缩方案。在此基础上,预测聚类的标签使「重新学习」的网络能够学习到对原始预训练目标不太敏感的特性,从而使这些特征更易于「迁移」。作者提出了几个下一步考虑的研究方向,包括:引入域知识、结合不同类型的预训练模型完成多任务学习、在聚类过程中引入证据积累(evidence accumulation)方法等。
3、Learning Representations by Predicting Bags of Visual Words

论文链接:https://arxiv.org/abs/2002.12247
自监督表征学习使用图像中的可用信息(例如,预测两个图像块的相对位置)定义的无标注预文本(unlabeled pretext)训练卷积神经网络(convnet),通过这样一个基于预文本的预训练,使得 convnet 能够学习到对一些视觉任务有用的表示,例如图像分类或对象检测等任务所需的表示。
一个值得探讨的问题是,究竟哪种自监督是有效的?
类似的,在自然语言处理(NLP)中,自监督方法在学习语言表示方面获得了巨大的成功,如 BERT 预测句子中的缺失单词等。NLP 与计算机视觉的不同之处在于:(1)与图像像素相比,文字能够表征更多的高级语义概念,(2)文字是在离散空间中定义的,而图像是在连续空间中定义的,这就导致对图像像素的小扰动虽然不会改变图像描绘的内容,但是却会显著的影响图像重建任务的效果。
尽管二者之间存在很大的不同,本文作者尝试借鉴 NLP 的思想,通过对离散视觉概念进行密集描述的方法,在图像处理任务中构建离散目标函数。首先采用一种自监督方法(如旋转预测法)训练一个初始 convnet,学习捕获中图像特征的比较抽象的特征表示。其次,使用基于 k-均值的词汇库对基于 convnet 的特征映射进行密集量化,从而得到基于离散编码(即 k-均值聚类分配)的空间密集图像描述,也就是所谓视觉单词(visual words)。经过这次离散化的图像处理后,使我们借鉴 NLP 的自监督学习变为可能,例如,可以很好地训练一个类似于 BERT 的体系结构,该体系结构作为图像中的图像块的一个子集输入,预测缺失图像块的视觉单词。本文作者从计算机视觉中所谓的词袋(Bag-of-Words,BoW)模型中获得灵感,提出将其作为一个自监督的任务训练一个 convnet 来预测图像视觉单词的直方图(也称为 BoW 表示)。完整的基于视觉词袋预测的自监督表示学习流程见图 1。

图 1. 视觉词袋预测学习表示
给定一个训练图像 x,第一步,使用预先训练的 convnet 创建一个基于空间密集视觉词的描述 q(x)。利用 k-均值算法将 K 个聚类应用于从数据集中提取的一组特征图,通过优化以下目标,学习视觉词汇的嵌入特征:

令Φ^(x) 表示输入图像 x 的特征图,Φ^u(x) 表示对应第 u 个位置的特征向量,对于每个位置 u,将相应的特征向量Φ^u(x) 赋给其最近的(以平方欧式距离为单位)视觉词嵌入 q^u(x):

第二步,创建图像 x 的离散表示 q(x) 的 BoW 表示:y(x)。可以采用两种表示形式:


y(x) 是一个 k 维向量,其中第 k 个元素 y_k(x) 编码第 k 个视觉词在图像 x 中出现的次数。结果 y(x) 可以被看作是图像 x 的第 K 个视觉词的软分类标签。K 值可能较大,因此 BoW 表示 y(x) 是相当稀疏的。
第三步,基于提取的 BoW 表示,执行自监督任务:给定图像 x,使用扰动算子 g(·) 生成扰动图像 x˜=g(x),然后训练模型基于扰动图像 x˜「预测/重建」原始图像 x 的 BoW 表示。本文使用的扰动算子 g(·):包括(1)颜色抖动(即图像的亮度、对比度、饱和度和色调的随机变化);(2)以概率 p 将图像转换为灰度;(3)随机图像裁剪;(4)比例或纵横比失真;(5)水平翻转。
定义一个预测层Ω(·),该预测层以Φ(x˜)作为输入,输出 BoW 中的 K 个视觉词的 K 维 softmax 分布。该预测层通过 liner-plus-softmax 层实现:

其中,W = [w_1,· · · ,w_K] 是线性层的 K 个 c 维权重向量(每个视觉词一个)。为了学习 convnet 模型,最小化预测的 softmax 分布Ω(Φ(x˜))和 BoW 分布 y(x)之间的期望交叉熵损失:


其中,loss(α, β) 为交叉熵损失。
训练前随机初始化Φ(·),之后,在自监督学习过程中每次使用先前训练的模型Φˆ(·)生成 BoW 表示。作者表示,第一次迭代后得到的模型已经具有较好的效果,因此,一般只需要执行一至两次迭代就可以得到最终结果。
实验分析
本文在 CIFAR-100、Mini-ImageNet、ImageNet、Places205、VOC07 分类和 V0C07+12 检测数据库中上评估了所提出的方法(BoWNet)。
表 1. CIFAR-100 线性分类及少样本测试结果,其中,Φˆ(·)采用 WRN-28-10 架构实现

表 2. Mini-ImageNet-100 线性分类及少样本测试结果,其中,Φˆ(·)采用 WRN-28-10 架构实现

表 1 和表 2 给出了 CIFAR-100 和 Mini-ImageNet 库上的结果。通过比较 BoWNet 和 RotNet(用于构建 BoWNet)的性能,实验结果显示 BoWNet 将所有的评估指标至少提高了 10 个百分点,迭代使用 BoWNet(BoWNet×2 和 BoWNet×3)能够进一步提高分类任务的准确度(除了 one-shot 的情况)。此外,在表 1 给出的 CIFAR100 线性分类任务的结果数据中,BoWNet 性能大大优于最近提出的 AMDIM。在表 2 给出的 Mini-ImageNet 库的分类任务结果数据中,BoWNet 的性能与有监督 CC 模型的性能非常接近。
表 3. ResNet-50 线性支持向量机的 VOC07 图像分类结果

在 VOC07 库中使用 Goyal 等人提供的公开代码对自监督方法进行基准测试,在冻结学习表示的基础上训练线性 SVM,其中,使用 VOC07 训练+验证数据子集进行训练,使用 VOC07 测试子集进行测试。实验中考虑了第三(conv4)和第四(conv5)残余分块的特征,结果见表 3。表 3 中的实验数据显示,BoWNet 优于所有先前的方法。
表 4. ImageNet 和 Places205 中线性分类准确度(使用 ResNet-50 结构)

使用基于冻结特征表示的线性分类器对 1000-way ImageNet 和 205-way Places205 的分类任务进行评估。表 4 中的实验数据显示,BoWNet 优于所有先前的自监督方法。此外,在 Places205 中,使用本文方法训练的 ImageNet 的 BoWNet 表示和 ImageNet 训练得到的有监督表示之间的位置的精度差距仅为 0.9 points。作者认为, 这表明了对于「训练阶段看不到的」Places205 的类别,使用本文提出的方法得到的自监督表示与有监督方法得到的表示具有几乎相同的泛化能力。
表 5. V0C07+12 的目标检测任务结果(使用快速 R-CNN 微调结构)

将 BoWNet conv4 和 BoWNet conv5 与经典的和最新的自监督方法进行了比较,结果在表 5 中。有趣的是,在作者给出的这个实验结果中,BoWNet 的性能优于有监督的 ImageNet 预训练模型,后者在与 BoWNet 相同的条件下进行微调。基于这个实验结果,作者认为, 本文提出的自监督表示比有监督表示更适用于 VOC 检测任务。
小结
本文提出了一种新的表示学习方法 BoWNet,该方法以视觉词汇的空间密集描述为目标进行自监督训练。由本文的实验和分析可知,BoWNet 是在无标签监督的情况下学习的特征上训练的,但它获得了很好的效果,甚至优于了初始模型。这一发现以及特征空间的离散化处理(变成视觉词汇)为后续的研究提供了新的思路。
4、AdderNet: Do We Really Need Multiplications in Deep Learning?

论文链接:
https://arxiv.org/pdf/1912.13200
加法、减法、乘法和除法是数学中最基本的四种运算。众所周知,与加法相比,乘法计算复杂度高、计算速度慢。在深度神经网络中,度量输入特征与卷积滤波器的相似性是通过计算大量的浮点数相乘来实现的。在这篇文章中,作者提出了一种加法器网络(AdderNet),在放弃卷积运算的同时最大限度地利用加法,即,给定一系列小模板作为「神经网络中的滤波器」,使用 L1-norm 距离计算输入信号和模板之间的差异。图 1 中对比了经典 CNN 与本文提出的 AdderNet 提取特征的可视化展示。CNN 是通过角度来区分不同类别的特征,而使用 L1-norm 距离的 AdderNet 则是通过向不同类别的类中心聚集来区分别不同类别的特征。由于减法可以通过其补码通过加法实现,因此 L1-norm 距离可以是一种硬件友好的仅具有加法的度量,作者认为,它可以成为构造神经网络的卷积的有效替代方法。

图 1. AdderNets 和 CNNs 中特征的可视化
模型介绍
给定一个深度神经网络的中间层,考虑一个滤波器 F,其中核大小为 d,输入通道为 c_in,输出通道为 c_out。输入特征定义为 X,令 H 和 W 分别为特征的高度和宽度,输出特征 Y 表示滤波器和输入特征之间的相似性,得到公式:

其中,S(·,·)表示预定义的相似性度量。如果使用互相关性作为距离度量,即 S(x,y)=x×y,则上式为卷积运算。此外,还有许多其他的度量能够用来测量滤波器 F 和输入特征 X 之间的距离。然而,这些度量中的大多数涉及乘法运算,具有较高的计算成本。因此,本文作者使用加法测量距离。L1-norm 距离计算的是两个矢量表示的绝对差之和,它不包含乘法运算。此时,相似性计算公式为:

经典 CNN 中,作为输入特征映射中的值的加权和,卷积滤波器的输出可以是正的或负的,但是加法器滤波器的输出总是负的。因此,引入批量归一化将加法器的输出层规范化到一个适当的范围内,然后在所提出的加法器中使用经典 CNN 中使用的所有激活函数。尽管在批量规范化层中涉及乘法运算,但其计算成本明显低于卷积层,可以省略。
模型训练
神经网络利用 BP 反向传播计算滤波器的梯度,利用随机梯度下降更新参数。在经典 CNN 中,输出特性 Y 相对于滤波器 F 的偏导数计算为:

其中,i∈[m,m+d],j∈[n,n+d]。在 AdderNet 中,输出特性 Y 相对于滤波器 F 的偏导数计算为:

其中 sgn(·)表示符号函数,梯度值只能取 1、0 或-1。然而,signSGD 几乎不接受最陡下降的方向,使用 signSGD 对大量参数的神经网络进行优化是不合适的。本文使用下式优化:

除了滤波器 F 的梯度外,输入特性 X 的梯度对于参数的更新也很重要。因此,本文也使用上式计算 X 的梯度。为了防止计算 X 梯度时出现梯度爆炸的问题,将 X 的梯度限制在 [-1,1] 区间中。输出特性 Y 相对于输入特性 X 的偏导数计算为:

其中,HT(·)表示 HardTanh 函数:

自适应学习速率尺度
经典 CNN 中,假设权值和输入特征是独立的,并且在正态分布下分布一致,则输出方差可以粗略估计为:
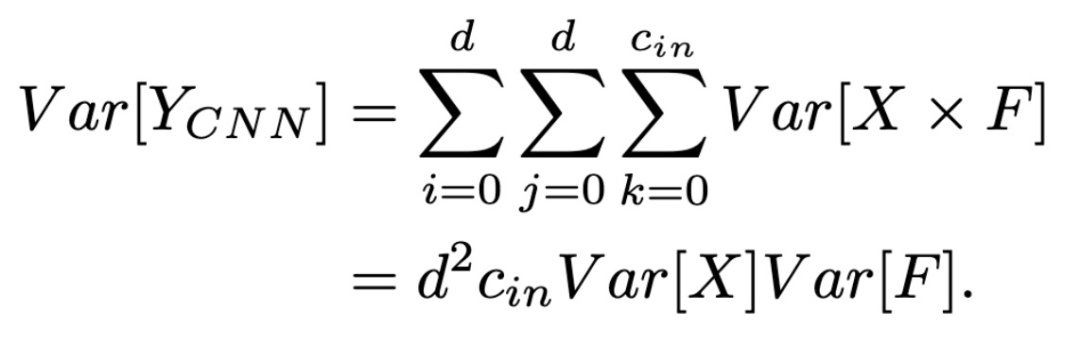
而对于 AdderNet,输出方差可以近似为:

其中 F 和 X 服从正态分布。由此可见,与经典 CNN 较小的 Var 值不同,AdderNet 中的加法运算会导致加法器的输出方差数值较大。本文提出了一种自适应学习方法,即在 AdderNet 的不同层中采用自适应的学习效率,具体的,AdderNet 中每层 (l) 的更新为:

其中,γ为整个神经网络的全局学习率,∆L(F_l) 是滤波器的梯度,α_l 为相应的局部学习率,具体的:

其中,k 表示 F_l 中平均 L_2 范数的元素个数,η是控制加法器滤波器学习速率的超参数。
通过自适应学习速率调整,可以用几乎相同的步骤更新不同层的加法器滤波器。算法 1 给出 AdderNet 的训练过程。

实验结果
AdderNet 在大规模神经网络和数据集上取得了非常好的表现,包括 MNIST,CIFAR,ImageNet。在 MNIST 中的分类结果如表 1。与 CNNs 相比,AdderNet 在没有进行乘法计算的前提下,获得了几乎相同的结果。
表 1. CIFAR-10 和 CIFAR-100 数据集上的分类结果

表 2.ImageNet 数据集上的分类结果

在 ImageNet 中的分类结果如表 2。与 CNNs 相比,AdderNet 在没有进行乘法计算的前提下,Top-1 和 Top-5 的结果与 CNN 接近。而 BNN 尽管能够实现高计算速率和高压缩比,但是分类效果较差。

图 2. MNIST 数据集上 LeNet-5-BN 第一层过滤器的可视化。这两种方法都能为图像分类提取有用的特征
图 2 给出的是 MNIST 数据集上的可视化效果。尽管 AdderNet 和 CNN 使用不同的距离度量,但是 AdderNet 的滤波器仍然能够提取与卷积滤波器所提取的相似的特征。可视化实验进一步证明,AdderNet 能有效地从输入图像和特征中提取有用信息。
小结
本文探讨的是在深度神经网络中使用加法计算替代乘法计算的可能性,给出的实验结果证明了 AdderNet 能在不使用乘法计算的前提下,获得与经典 CNN 相当的分类效果,此外所提取特征的可视化也显示出 AdderNet 所提取的特征与经典 CNN 类似。不过,在这篇文章中,作者并没有给出关于计算速率、时长、消耗的定量分析结果。作者提出,下一步的研究计划是分析 AdderNet 的量化结果,以实现更高的速度和更低的能量消耗。此外,将探讨 AdderNet 的通用性,将其应用于检测和分割任务中。
作者介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
阅读原文,提交申请。游戏网
| 相关下载 |

原标题:2020智能物流产业研究报告 侠说涵盖数千份互联网、短视频、房地产、金融科技、市场运营等报告,下载报告请关注微信公众号《侠说》,入圈下载,坚详情>>

符合购房资格可买,有资格就可以买,不能哦详情>>
原标题:中国疾控中心研究员:无症状感染者不会造成传播扩散 3月24日下午,国务院联防联控机制召开新闻发布会,介绍新冠肺炎疫情防控与医疗诊治有关情况详情>>

原标题:美国陆军研究人员要求业界寻求可信战术网络信息安全的新方法 [据军事宇航网站2019年11月26日报道]美国马里兰州阿伯丁试验场——美国陆军研详情>>
原标题:中思拓研究院简介 中思拓研究院2019年正式成立。响应中央号召,“要运用大数据提升国家治理现代化水平”,推动优化经济治理基础数据库,是致力于详情>>

原标题:南太湖社会治理研究院在织里成立 人民网湖州市11月17日电 (记者李锋)由多名中外知名专家、学者组成的南太湖社会治理研究院11月17日在浙江详情>>

原标题:美国历史研究者撰文:1918年大流感的应对为何失败? 1918—1919年横扫世界的“大流感”(The Great Influenza,也被称为“西班牙大流感”),据估计夺去了5详情>>

原标题:艾瑞咨询:2019年中国游戏直播行业研究报告 2019年游戏直播行业发展进入成熟期,平台间的竞争与离场给市场带来新活力;头部平台收入的迅速增长有详情>>

柱子英雄手游中研究所十分重要,研究所有什么用呢?研究所用处有哪些呢?今天小编就带来一篇柱子英雄研究所攻略大全 研究所用处详解,一起来看看吧:研究所攻略大全优先随等级解锁战详情>>
如果年龄超过40岁了,应该不具备人才房申请资格。 人才购房对象有七类: ①在我市工作,相当于《南京市人才安居办法》中的A—E类人才; ②在我市工作,取得博士学位的人才; ③在我详情>>

原标题:安全研究员发现 iPhone 11 Pro 在关闭定位服务后仍会收集定位数据 苹果向来强调隐私保护,但最近有安全研究人员发现,即使关闭了定位服务,iPho详情>>

这次S10季前赛版本改动了野区的经验收益,削弱了石甲虫经验提高了魔沼蛙经验,所以任何半区的三组野都可以到3级,打野英雄到三级的时间点相比之前版本提前了一个野怪的时详情>>

原标题:SEO研究者:如何规划网站建设和网站推广的内容 在现有的互联网世界中,SEO worker的范畴下所能包含的具体工作内容,可谓繁杂无比:网站内容制作、详情>>

原标题:研究人员开发出新型节能芯片来唤醒小型无线设备 加州大学圣地亚哥分校的工程师们发明了一种新型节能芯片,可以大大减少或消除物联网设备和可详情>>

原标题:国务院发展研究中心宏观部与百度地图研究成果亮相 【环球网科技综合报道】11月9日消息,国务院发展研究中心宏观经济研究部和百度地图联合举详情>>

原标题:双一流高校拟清退一批研究生!网友点赞 导读 没有毕不了业的大学生? 日前,复旦大学研究生网发布《2019-2020学年第一学期研究生退学决定公示(第详情>>

15岁女蝉联科学家是什么情况,在大家的印象中,想必科学家都是比较有岁数的成年人,但日前,年仅15岁女蝉联科学家引起大家的热议,大家都很好奇这个女孩子是怎么详情>>
央视新闻客户端10月31日消息,在全球经济放缓的大背景下,面对经济不确定性和融资市场震荡,美联储在今年内采取了包括“扩表”和降息在内的一系列行动。然而日前,有美国学者发布研详情>>
今年 8 月,苹果起诉了一家名叫 Corellium 的企业,理由是该公司的 iOS 移动设备虚拟化方案,侵犯了在 iPhone / iPad 上运行的这款操作系统的版权。今天,Corellium 对苹果的诉讼详情>>
原标题:360金融宣布成立隐私保护与安全计算研究院 进入9月以来,中国的金融科技行业进入了一个前所未有的“整顿期”。已有多家第三方大数据公司被纳详情>>

据外媒报道,来自英国的研究人员分析了饮食与勃起时间的关系,发现吃红肉越多的男性勃起时间越短。 美国泌尿学会前首席代表亚伦·斯皮茨(Aaron Spitz)博士说:“详情>>
原标题:中国联合办公行业研究报告:商业模式完整 本土优势明显 日前,全球企业增长咨询公司沙利文发布了《中国联合办公行业研究报告》(以下简称“报告详情>>

原标题:倪光南院士:国产操作系统需要生态支持,要加大基础研究工作 10月20日上午,第六届世界互联网大会在乌镇互联网国际会展中心乌镇厅开幕,开幕式上中详情>>
原标题:英飞拓:成立英飞拓研究院 证券时报e公司讯,英飞拓(002528)9月5日晚间公告,公司决定成立英飞拓研究院。英飞拓研究院目前正在致力于人工智能、详情>>

原标题:快舟一号甲火箭发射成功 天仪研究院完成第八次太空任务 新京报讯(记者 陆一夫)8月31日上午7点41分,由中国航天科工航天三江集团所属航天科工详情>>

港科大海洋研究项目获广州批3800万元人民币 实现大湾区跨境科研资金流动 新华社香港8月21日电(记者张雅诗)香港科技大学20日宣布,该校于8月1日获广州方面批出3800万元人民币(详情>>

《缺氧》研究站制作及用途介绍。在缺氧中我们需要制作各式各样的建筑或者道具,当然都是五花八门的建筑物啦,那么这些建筑物在缺氧中制作的时候需要什么材料,以及他们的作用是详情>>

焦点网友156810117 1小时前 安发国际和很多国内外知名高校及研究机构都有合作的,比如新西兰皇家科学院、新西兰奥克兰大学、国内的话我记得有上海交大、华东师大详情>>

关于屁的研究!这是一个有味道的研究! 详情>>

VR之家消息:随着键盘的问世,键盘便成为了主要的输入方式。如果有一天,我们所使用的键盘变成了VR触摸隐形键盘,这将是件多么酷的事情。一起来了解一下更多关于VR触摸隐形键盘详情>>

VR之家消息:近日,澳大利亚皇家墨尔本理工大学Exertion Games Lab的研究人员进行了一次有趣的研究:他们一直在尝试将大脑脑波与虚拟现实结合起来整合成一种VR摇篮机。 详情>>
原标题:腾讯联合北大等多所大学创立游戏学研究共同体,发布国内首部研究专著《游戏学》 据界面新闻消息,昨日,北京大学互联网发展研究中心、上海交通大学设计学院、详情>>

《赤痕:夜之仪式》是一款不错的动作角色扮演游戏,游戏发售后,Steam好评率达90%以上。相比去年的版本,游戏画质得到了很大提升,展现出了独特的美术风格。这个游戏中有大量的成就详情>>

在乱世王者中想让自己的基地强大起来主必须研究一些科技,比如发展科技、军事科技、资源科技等等。接下来教大家怎么简单的研究一些的科技。攻略对象乱世王者步骤分解1在游戏详情>>
原标题:国内首部游戏学研究专著发布 联合打造游戏学研究共体 1月9日上午,由北京大学新媒体研究院、北京大学互联网发展研究中心、腾讯研究院、腾讯游戏学院联合主详情>>
《漫威蜘蛛侠》完成全部研究站任务后可获得奖杯:研发部门,同时可以获得很多研究代币,这些任务怎么完成呢?下面就为大家带来漫威蜘蛛侠全研究站任务视频攻略,一详情>>

原标题:研究人员发布了第一个判断“游戏障碍”倾向的心理测试 你能得几分? 经过长期的争议后,“游戏障碍”在上周作为被世界卫生组织(WHO)认定的一种疾病正式出现详情>>

原标题:名校们开始研究“游戏学”, 研究的是什么? 对于中国游戏史而言,2018是不平凡的一年。 年初,“佛系 详情>>

《菇菇栽培研究室》的豪华版也就是DX版是木木认为最值得体验的一个版本,因为每个月游戏都会定期进行更新保持新鲜感。今天木木就为大家带来 详情>>

4月15日,市场研究公司Zion发布了一份关于VRAR在医疗领域市场的报告。该报告内容涵盖全球行业观点,综合分析和预测,跨越时间段为2018年-202详情>>


































